DeepSeek’s Evolution
After a 16-month wait, the anticipated Chinese AI showcase, DeepSeek V4, finally debuted ahead of the May Day holiday.
This week, alongside DeepSeek, competitors like Qwen, Kimi, Xiaomi, and Tencent also unveiled their latest innovations.
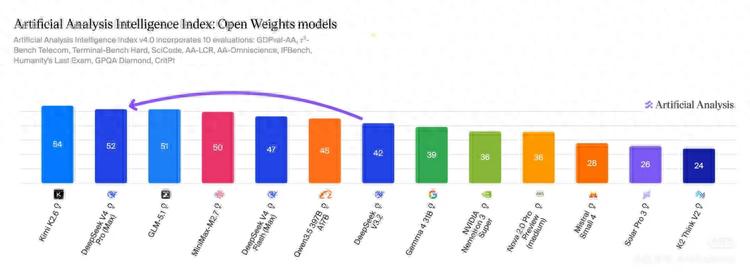
According to the latest open-source model intelligence index from Artificial Analysis, the top ranks are now dominated by Chinese models, with the top two being released this week. These companies have also entered the global top five for real usage on OpenRouter.
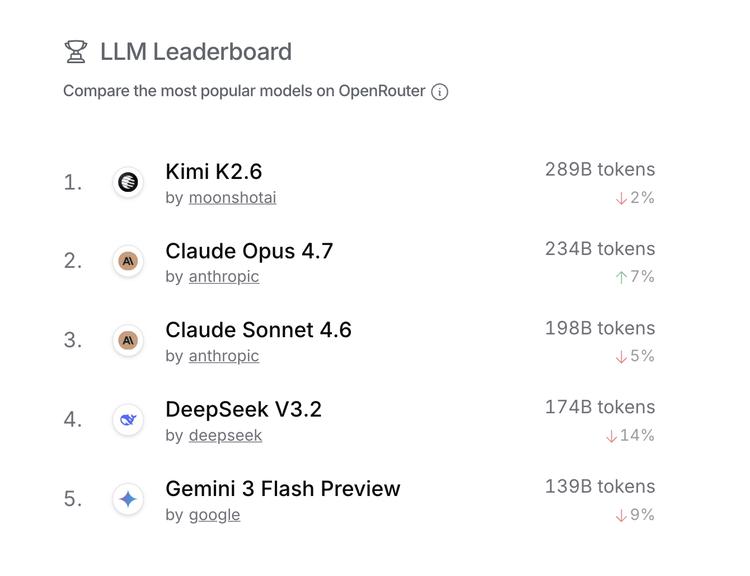
The synchronized launches of DeepSeek and Kimi are no longer mere coincidences. Looking back at previous releases:
- In January 2025, DeepSeek R1 and Kimi K1.5 were released within hours of each other, both targeting OpenAI.
- A month later, DeepSeek NSA and Kimi MoBA appeared simultaneously, both focused on transforming the core attention mechanism of Transformers.
- In April 2025, Kimi’s Kimina Prover Preview and DeepSeek-Prover-V2 were released, advancing formal mathematical reasoning and theorem proving.
Now, a year later, Kimi K2.6 and DeepSeek V4 are released in the same week, both trillion-parameter open-source models hitting the stage.
What’s New This Time
Let’s examine what each has brought to the table.
DeepSeek V4 is a 16 trillion parameter MoE model, featuring 49 billion active parameters and native support for 1 million tokens of context. Its core narrative revolves around an efficiency revolution, with a 73% reduction in computational requirements for single token inference compared to the previous V3.2, and KV cache compression down to one-tenth of its original size.
In simpler terms, the same hardware can handle significantly more requests, and the cost for processing the same length of text is much lower.
Additionally, V4 has achieved deep adaptation for Huawei’s Ascend chips, migrating its underlying code from NVIDIA’s CUDA ecosystem to Huawei’s CANN architecture, adding a layer of domestic computing power transition to this release.
Kimi K2.6 is a trillion-parameter MoE multimodal model with 32 billion active parameters and 256K context. Its focus is not on being larger or cheaper, but on being more enduring.
In tests, K2.6 can continuously code for 13 hours, handle over 4000 tool calls, modify more than 4000 lines of code, and complete a near-performance-limit deep reconstruction of an open-source financial matching engine.
This is not just an ordinary enhancement of coding capabilities; it tests whether the model can transition from one-off responses to long-term, multi-tool, multi-Agent collaborative work.
K2.6 also introduces an Agent cluster architecture, supporting 300 sub-Agents working in parallel. The RL infrastructure team at Dark Side of the Moon has already run K2.6-driven Agents autonomously for five days, managing monitoring, fault response, and system operations.

While both models meet at the same crossroads, their trajectories diverge. At least in this round, one seems to be rewriting the cost structure of model infrastructure, while the other is validating whether models can engage in longer-term real tasks. Despite their different directions, the fact that they were released in the same week is noteworthy.
Both companies have made consistent choices: trillion-parameter MoE architecture, open-source, and continued belief in Scaling Law. To date, they are the only two open-source trillion-parameter models in China.
More Interesting Than a Collision
The repeated synchronicities are amusing, but they also highlight a more significant phenomenon: the technological paths of both companies are inspiring each other.
Previously, Kimi K2 drew inspiration from the MLA attention mechanism popularized by DeepSeek V3. MLA is a method that compresses attention computation and KV caching to enhance efficiency, making it a prominent option in the Chinese open-source model tech stack.
This time, DeepSeek V4 has adopted the Muon optimizer as one of its three major updates at the model architecture level. Muon is a second-order optimizer that addresses efficiency and stability issues during parameter updates in the training phase, replacing the decade-old Adam optimizer. Kimi was among the first teams to push the Muon optimizer to trillion-parameter-level training and share their experiences publicly, with Yang Zhilin stating at GTC 2026 that it could double token efficiency. V4 also follows suit by using the Muon optimizer to enhance convergence efficiency and training stability.
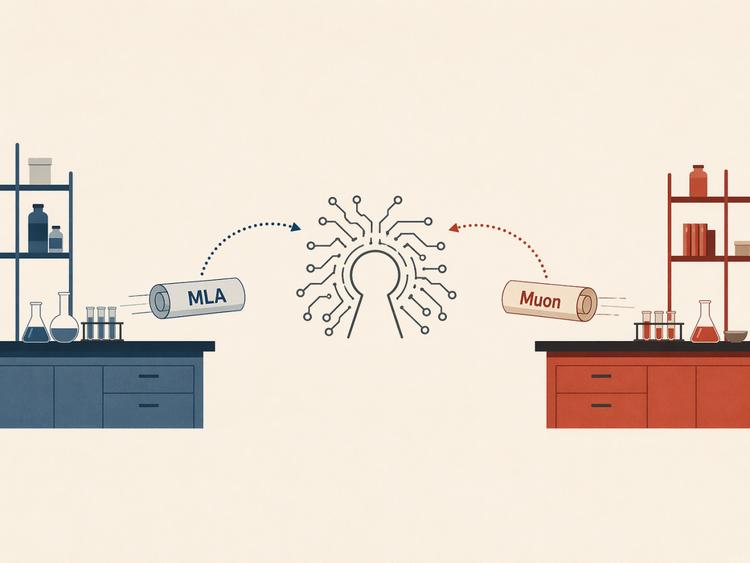
In other words, MLA saves costs during inference, while Muon saves time during training. These paths have already traversed back and forth between the two companies.
This makes the “collisions” not just a coincidence in release timing but a resonance at the technological stack level. It resembles a competitive yet collaborative environment where both companies transform each other’s explored technological ideas into reference points for their next experiments.
This mutual inspiration continues to extend. In attention mechanisms, DeepSeek explores sparse attention, while Kimi’s next-generation model investigates linear attention. Although the paths differ, the questions they aim to answer are the same: how to manage long contexts without being overwhelmed by the computational complexity of full attention.
In residual connections, DeepSeek employs mHC, while Kimi uses attention residuals, both targeting the same goal of maintaining training stability as models deepen.

This phenomenon is noteworthy because, in a broader industry context, it is quite unusual. Leading companies in Silicon Valley are becoming increasingly closed off; OpenAI has long ceased to disclose training details, and core methods from Anthropic and Google are similarly opaque, leaving the community to speculate and piece together their technological routes.

In contrast, the visibility of technical reports and open-source code between Kimi and DeepSeek significantly shortens the chain of technological diffusion. The repeated collisions can be seen, discussed, and compared precisely because both companies have chosen to lay their advancements on the table.
The speed of technological diffusion in Chinese open-source models is becoming much faster than before. This may be the true implication of frequent collisions.
Global Tech Community is Watching Their Collisions
This narrative of “collisions” was initially coined by the Chinese tech community. However, the overseas developer community is also confirming this phenomenon in their way.
After the release of K2.6, one of the most influential newsletters in the AI field, Latent Space, placed Kimi as the leader of Chinese open-source model labs after DeepSeek’s silence. A few days later, with the release of V4, the overseas developer community quickly compared V4, K2.6, and GLM 5.1 in terms of parameters, pricing, context length, and Agent capabilities.

Chinese models showcased at NVIDIA’s GTC 2026 for demonstrating next-generation chip inference performance are these two.
In the overseas developer community, Kimi and DeepSeek are increasingly being included in the same discussions about Chinese open-source models.
They Are Not Colliding with Each Other
This situation has made the relationship between DeepSeek and Kimi somewhat delicate. They are undoubtedly competitors, but in the broader model ecosystem, they are jointly elevating the visibility of Chinese open-source models.
The pressure they exert on closed-source models does not come from a single benchmark but from slower, foundational variables like cost, deployability, open-source weights, and the speed of technological diffusion.
So, did Kimi intentionally collide with DeepSeek?
Most likely not. Developing trillion-parameter MoE models, modifying long-context attention mechanisms, optimizing training efficiency, adapting to domestic chips, and genuinely opening up their models are not mere “options” but “necessary paths.”
Both companies are diligently working on foundational technologies and have chosen to place key advancements in the public domain, leading them to meet repeatedly at the same crossroads.
It’s not that they are too in sync; it’s that the road is too narrow.
As for the next “collision,” it is likely already on the way. If I’m not mistaken, Kimi’s approach to synchronizing text and visual capabilities in large models will inspire more Chinese open-source pure text models to develop “eyes” and see a broader, larger world.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.